[BLOG] DER DIGITALE KONTROLLVERLUST
Als Kind in den 90er Jahren konnte ich über eine Sache unendlich staunen – die Geheimnisse der Technik. Sie nur zu benutzen hat mir aber nicht genügt. Ich habe sie voller Neugierde und zum Leid meiner Eltern unter dem Vorwand der „Reparatur“ brachial aufgebrochen, um an die Geheimnisse zu kommen, die in ihrem Inneren versteckt waren. Die Hüllen waren auch schnell durchdrungen, aber die Rätsel der seltsam anmutenden Drähte, Platinen und Schaltungen blieben zum Teil bis heute.

Fast Forward ins Jahr 2021. Die Geräte sind schlauer (nein, smarter) geworden und wir stellen uns ganz andere Fragen über sie, als noch in den 90ern. Telefoniert meine Fernbedienung heimlich mit den mächtigsten Unternehmen? Belauscht mich mein Smartphone? Ist das Paranoia? Kann ich meinen Freunden eine Nachricht schreiben, ohne dass sie mitgelesen oder verändert wird? Werden sich meine Daten irgendwann gegen mich wenden? Tut das Gerät das, was es verspricht? Oder noch mehr?
Diese Fragen sind in Wahrheit so umfangreich, dass es uns oft ratlos auf die Maschinen staunend zurück lässt, unbefriedigt und überfordert. Wie kann ich die Kontrolle über mein digitales Leben haben, wenn ich keines der Geräte wirklich komplett verstehe? Dann nimmt unsere Hilflosigkeit gegenüber der Technik oft den Charakter des Mystischen an: Gekoppelt an die wage Vorstellung, das wohl irgendwo Menschen hinter ihren Bildschirmen sitzen, die alle Baupläne, Codes und Netzwerke durchblicken. Aber es ist leider viel komplexer als das.
Können wir die Kontrolle, oder Nachvollziehbarkeit, unserer digitalen Welten erhalten? Und wenn nein – an welchen Enden ist sie uns entglitten, und warum?
Die Anfänge: Der Mensch in der Maschine war leicht zu entdecken
Ein frühes Beispiel für eine Maschine als geheimnisvolle Blackbox begegnet uns schon im Jahr 1770. Der Mechaniker Wolfgang von Kempelen baute einen Scheinroboter, den er, heute unvorstellbar, „Schachtürken“ nannte. Dieser Roboter sollte selbstständig gegen einen Menschen Schach spielen können, etwa 200 Jahre bevor die ersten richtigen Schachcomputer entwickelt wurden. Die Maschine war selbstverständlich ein Schwindel. Im Inneren des Roboters saß ein Mensch, der den Roboter über eine Mechanik steuerte. Das Publikum aber wurde im Glauben gelassen, der Apparat würde selbständig spielen. Die Menschen waren begeistert – es hat ihre Fantasie angeregt. Die Maschine war geheimnisvoll wie ein Zaubertrick. Das Verborgene war seine Größe.
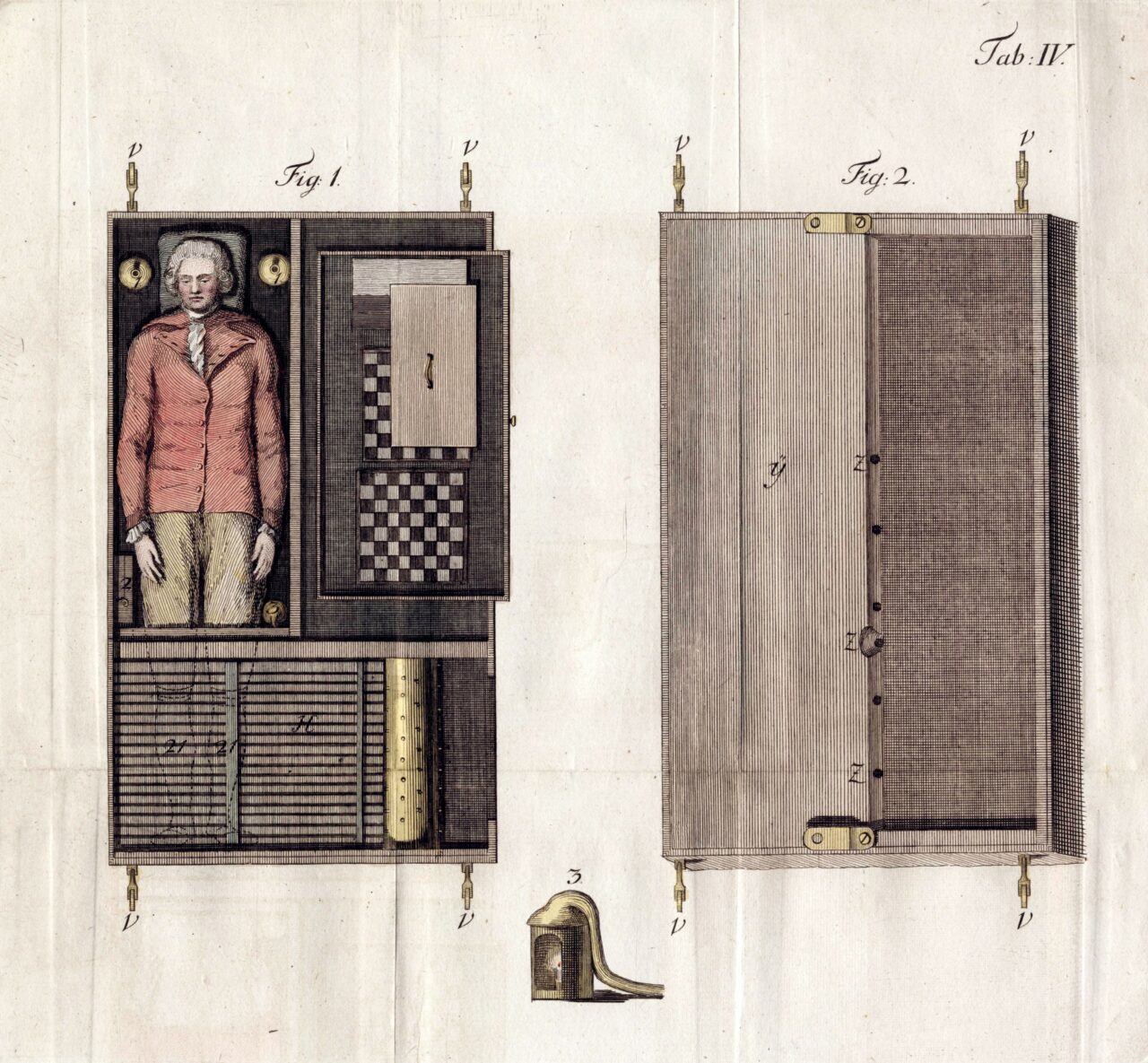
Heutige Maschinen haben eine ähnliche Wirkung wie der Scheinroboter im Jahr 1770 – das Innere ist ein Rätsel. Eine Sache hat sich aber fundamental geändert. Hätte damals jemand in den „Roboter“ hineingesehen, wäre beim Anblick des Menschen, der die Fäden zieht, jedes Geheimnis gelüftet gewesen. Anders als heute, wo uns ein Blick hinter die Gerätehüllen eines Computers recht wenig über dessen Funktionsweise verrät. In den 250 Jahren, die seither vergangen sind, hat die Intransparenz radikal zugenommen während die Möglichkeiten zur Kontrolle massiv abgenommen haben.
Oft wissen wir gar nicht, mit welcher Maschine wir es eigentlich zu tun haben. Kaufen wir einen Computer, erhalten wir ein Gerät, dass sich über die Internetverbindung erweitert und verändert. Das Produkt ist ein Prozess. Die Updates hören nie auf – und wenn doch, ist das Gerät unbrauchbar geworden, weil ohne den Sicherheitsupdates ist es den Anforderungen des Netzes nicht mehr gewachsen. Können wir also überhaupt sagen, womit wir es zu tun haben, wenn es sich doch von Anfang an im Wandel befindet?
Das sich hier etwas in den letzten Jahren schnell verändert hat zeigt sich auch in der Beobachtung der Techniker*innen. Ein klassischer Spruch typischerweise eher betagter Systemadministrator*innen ist: „Never touch a running machine“. Sie haben gelernt, dass ein funktionierendes System am besten weiter funktioniert, indem man keine Parameter verändert. Dieses Prinzip ist aber schneller veraltet, als die Generationen wechseln konnten. In der prozesshaften Funktionsweise der vernetzten Maschinen agiert alles miteinander und beinflusst sich gegenseitig. Wird hier nicht vorbeugend kontrolliert und eingegriffen, erleben die Administrator*innen schnell böse Überraschungen. Das ist ein Paradigmenwechsel, durch den es nicht zuletzt massiv schwerer geworden ist, wirklich stabile und gut durchdachte Systeme zu entwickeln. Kritische Infrastruktur ist davon besonders gefährdet, wenn neue Technik schneller Einzug hält, als sich Expert*innen mit den neuen Gegebenheiten befassen können.
Macht der Computer im Hintergrund wirklich genau das, was man glaubt?
Wenn wir ein stabiles System haben wollen, das transparent und verlässlich, allen Menschen zuträglich arbeitet, müssen wir es bis ins kleinste Detail auseinandernehmen und nachvollziehen können. Was würden wir für so ein Unterfangen brauchen?
Stellen wir uns vor, wir haben einen betagten Computer vor uns, Baujahr 1995 und wir würden gerne verstehen, wie er funktioniert, weil wir uns wirklich auf ihn verlassen müssen. Wir würden auf unser Wissen der Informatik setzen – Softwareentwicklung, Elektronik, Datenverarbeitung und so weiter. Wenn wir uns dann die Hardware genauer ansehen, können wir zu Beginn noch recht einfach unterscheiden – das ist die Festplatte, das der Speicher, hier wird der Strom gewandelt, das ist der Prozessor. Wollen wir uns den Prozessor dann aber genauer ansehen, stoßen wir schnell auf eine große Hürde. Die Pläne für diese Bauteile sind proprietär – es ist zwar dokumentiert mit welchem Maschinencode man den Prozessor füttern kann um ein Ergebnis zu erwarten – aber Transparenz bleibt Unternehmensgeheimnis.
Wenn wir das weiter verfolgen wollen, müssen wir den Chip brachial öffnen, wodurch er unbrauchbar werden würde. Wir bräuchten ein Mikroskop um die winzigen Schaltungen im Inneren zu fotografieren und um die komplexen Logiken, die Wege der Elektrizität nachzubilden. Ein unvorstellbarer Aufwand, den sich speziell bei moderneren Systemen niemand mehr leisten könnte. Allerdings wäre es notwendig, denn wie laufend bekannt wird, gibt es viele Sicherheitslücken in diesen grundlegenden Bereichen der Datenverarbeitung, die auch mit Reverse Engineering nur schwer zu finden sind. Das diese oft jahrzehntelang unentdeckt bleiben, dürfte vor diesem Hintergrund nicht verwundern. Bei unserem Versuch einen alten Computer komplett zu verstehen stoßen wir also schnell auf unüberwindbare Hürden.

Die Nerds, die die Prozessoren zerlegen
Die Menschen hinter dem Projekt „Visual6502“ haben sich zum Ziel gesetzt, diese Blackbox zu öffnen und herauszufinden, was in ihrem Inneren wirklich vor sich geht. Sie veröffentlichten auf visual6502.org Simulationsmodelle von Prozessoren, die vor 1980 hergestellt wurden. Ihr Hauptprojekt ist die völlige Offenlegung des Designs des MOS 6502, eines populären Prozessors, der 1975 auf den Markt kam und einen erheblichen Beitrag zur Heimcomputerrevolution der 80er Jahre leistete.
Sie öffneten den Prozessor in einem aufwendigen Verfahren, fotografierten ihn und bildeten ihn digital nach, um die verborgenen Rechenschritte exakt simulieren und visualisieren zu können. Die daraus resultierende Simulation des 6502 kann man online abrufen – eine beachtliche, visuelle, blinkende Reizüberflutung. Dabei machten die Beteiligten eine interessante Bemerkung:
“While a multitude of people understand the instruction set for the 6502, almost no one, apart from the original designers, understands how the physical chip achieves this instruction set. The design is as elegant and sophisticated as any program written for the 6502.“
Mit erheblichem Aufwand wurde ein 45 Jahre altes Prozessordesign enthüllt und transparent gemacht – zumindest für dieses eine Exemplar des Prozessors. Der 6502 Prozessor hatte 3510 Transistoren verbaut. Zum Vergleich: Apple gibt an, dass in seinem im Jahr 2020 aktuellen M1-Prozessor 16 Milliarden Transistoren verbaut sind, also um den Faktor 4,5 Millionen mehr als in dem Design aus 1975. Man kann sich leicht vorstellen, welchen unvorstellbar höheren Aufwand es bedeuten würde, die Vorgänge in einem solchen aktuellen Chip transparent offenzulegen.

Im Hintergrund lauern die Sicherheitslücken
Wie komplex und schwer komplexe Systeme zu durchschauen sind, zeigen auch die darin vorkommenden Sicherheitslücken. 1995 sind Fehler in der Architekturentwicklung von Prozessorkernen gemacht worden. Niemand hat die Schwachstellen entdeckt, erst 22 Jahre später im Jahr 2017 sind Forscher von Googles „Project Zero“ sowie der TU Graz darauf gestoßen und haben die Fehler „Spectre“ und „Meltdown“ veröffentlicht. Betroffen waren beinahe alle Computer und auch viele Mobilgeräte, die zwischen 1995 und 2017 hergestellt wurden (darunter so gut wie alle Desktops, Apple-, Windows- und Unixrechner, iPads und iPhones, Android und viele mehr).
Durch diese Schwachstellen können Speicherbereiche im Prozessor ausgelesen werden, für die der jeweilige Prozess gar keine Berechtigungen hat – ein großer Angriffsvektor, 22 Jahre in vielen Milliarden Geräten unentdeckt. 22 Jahre, in denen alle Expert*innen glaubten, sie wüssten, wie ihre Systeme funktionieren, bis sie mit der Tatsache konfrontiert wurden, dass die Architekturen auf niedrigster Hardwareebene, im Chipdesign selbst, von Angreifern verwundbar sind.
Das ist nur ein Beispiel von vielen. Es spricht nichts dafür zu glauben, es wären die letzten Sicherheitslücken gewesen. 2021 ist in der universellen Turing-Maschine, dem einfachsten Bauplan für heutige Computer ein Fehler entdeckt worden – 54 Jahre nach Veröffentlichung dieser Referenzimplementierung. Obwohl der Fehler mit der Kennung CVE-2021-32471 keine reale Gefahr darstellt, ist es doch bezeichnend, dass sich überhaupt ein Fehler in die denkbar einfachste Umsetzung eines Computers einschleichen konnte und es 54 Jahre lang niemand gemerkt hatte.
Wir haben das Gefühl, dass wir die Systeme um uns herum kaum verstehen. Und wir haben recht damit. Unsere Möglichkeit der Kontrolle auf technischer Ebene ist sehr begrenzt. Auf der einen Seite komplexe Technik, die unser Vertrauen voraussetzt, auf der anderen Seite die Interessen der Entwickler und Politiker, die ihre Agenda in die Systeme integrieren. Neben Sicherheitslücken und Intransparenz sind Zensur, staatliche wie auch private Überwachung oder versteckter Datenhandel mindestens genauso große Probleme.
Fälle von digitaler Zensur sind allgegenwärtig. Man muss dafür gar nicht bis nach China oder Nordkorea schauen, es reicht ein Blick auf die EU oder Großbritanien. Der britische Mobilfunkanbieter Vodafone hat in Tansania SMS mit dem Namen des Oppositionsführers Tundu Lissu blockiert. Als Begründung wird angegeben, dass man sich an die örtlichen Gesetze halten müsse, selbst als britisches Unternehmen. Auch in Tansania haben die Menschen geglaubt, dass ein Knopfdruck auf „Senden“ eine Nachricht auch tatsächlich sendet – der Hintergrund bleibt verborgen.
Oder der teilstaatliche österreichische Mobilfunkkonzern A1, dessen Tochterfirma in Weißrussland Internetdrosselungen auf Verlangen des dortigen Diktators Lukashenko durchführt und seit einigen Jahren nahezu unbegrenzt Datenzugriffe des Regimes duldet. Die A1 Telekom Austria Group betont, dass das Unternehmen verpflichtet sei, sich an lokale rechtliche und regulatorische Vorgaben zu halten. Es bleibt die Frage – Was tut A1 um sich von dem blutigen Regime zu distanzieren?
Der Geist in der Maschine
Science- Fiction- Geschichten zeichnen dystopische Welten, in denen Maschinen den Menschen ablösen, ihm kognitiv und physisch überlegen sind. Die Urangst des Menschen, abgelöst zu werden, hat sich in ihrem Kern seit der Erfindung der Dampfmaschine kaum geändert. Der britische Mathematiker und Kryptologe I. J. Good hat in diesem Zusammenhang in einem Artikel aus dem Jahr 1965 geschrieben: „Eine ultraintelligente Maschine könnte noch bessere Maschinen entwickeln. Es gäbe fraglos eine ‚Intelligenzexplosion‘, und die menschliche Intelligenz geriete dabei weit ins Hintertreffen. Die erste ultraintelligente Maschine ist daher die letzte Erfindung, die der Mensch je machen muss – vorausgesetzt, sie ist so gefügig, dass sie uns verrät, wie man sie kontrolliert.“
So eine Dystopie scheint entweder übertrieben oder zumindest in weiter Ferne – interessant ist aber das, was sich im Verborgenen, hinter den Algorithmen, undurchsichtig und undurchdringlich komplex, heute schon schleichend normalisiert. Schwache künstliche Intelligenzen, bei denen sich Maschinen anhand von großen Datensätzen selbst trainieren, werden selbst von ihren Entwickler*innen oft nicht zur Gänze durchschaut.
Die Forscher*innen rund um die künstliche Intelligenz „Alpha Go Zero“ machten bei der Verbesserung ihres Systems eine Entdeckung. Die Maschine war programmiert worden, das traditionelle, hochkomplexe Spiel „Go“ zu spielen und die menschlichen Weltmeister zu besiegen. Der Durchbruch kam unerwartet plötzlich – anders als der Vorgänger der Maschine wurde Zero so programmiert, dass sie das gesammelte Wissen der Menschheit über Go ignorierte.
“Indem keine menschlichen Daten oder Erfahrungen verwendet wurden, befreiten die Zero-Entwickler die künstliche Intelligenz von den Fesseln menschlichen Wissens. Die Menschen, so stellte sich heraus, hätten das System gebremst. Die Leistung bestand in einer Systemarchitektur, die in der Lage war, ganz neu zu denken und eigene Entscheidungen zu treffen.“
Amy Webb in ihrem Buch „Die großen Neun“.
Die Algorithmen, die die Maschine erschuf, konnten selbst die Entwickler*innen nicht nachvollziehen. Das Verhältnis hat sich umgedreht und die Entwickler*innen lernen von ihrer eigenen Entwicklung, nicht umgekehrt. Man könnte hier auch argumentieren, dass im weitesten Sinn und trotz der Schwammigkeit der Begriffe der Sprung vom „Rechnen“ zum „Denken“ vollzogen wurde. Die Maschine fand Lösungsansätze, an die kein Mensch gedacht hatte. Wenn man den Output nicht erahnen oder deterministisch errechnen kann, dann ist das ein Kontrollverlust.

Wer sind die Entwickler*innen?
Die Macht dieser Entwicklungen lässt sich nicht wegdiskutieren. Aber welche Verantwortungen haben die Entwickler*innen an eine ethische Funktion dieser Technologie? Wer baut eigentlich die Maschinen, die unser Leben so maßgeblich beinflussen? Müssten diese Menschen nicht zumindest alles unter Kontrolle und den kompletten Einblick haben?
Es sind keine Einzelpersonen, die komplexe Maschinen bauen. Es sind Teams zu Hunderten oder Tausenden, deren Arbeit wiederum auf die von noch viel mehr Menschen aufbaut. Für Copy&Paste braucht es kein fundamentales Verständnis der Funktion – Vertrauen (oder Gleichgültigkeit) genügt. Es gibt in diesen Entwicklungsprozessen keine einzelne Person, die alles durchblickt.
Aber wer ein System entwickelt hat maßgeblichen Einfluss, wie sich das fertige System verhält – wem es nützlich ist und wem weniger, wem es nachempfunden ist, und wem weniger. Die Persönlichkeit der Entwickler*innen landet unweigerlich in dem Charakter der Maschinen. Es gibt unzählige Beispiele, in denen Maschinen dadurch rassistische Verzerrungen wiedergegeben haben, oder soziale Missstände ausgelöst haben.
Der Programmierer Melvin Conway stellte 1968 fest, dass Systeme die Menschen, die sie entwickelt haben und ihre Werte spiegeln. Dieser Effekt wurde später am MIT und der Harvard University weiter untersucht und ist heute als Conways Gesetz bekannt. Für künstliche Intelligenzen bedeutet das, dass auch die persönlichen Vorstellungen und die Ideologien der Entwickler*innen sich an die KI‘s vererben und KIs – gewollt oder nicht – einen Teil deren Werte annehmen.
KIs werden zu einem großen Teil von Menschen entwickelt, die besser situiert und gut gebildet sind und die entweder in Kalifornien oder China leben. Gleichzeitig entwickeln sie die Systeme, die auch alle anderen Menschengruppen betreffen und beeinflussen – und zwar nach ihren eignen Wertvorstellungen. Die Systeme und Produkte, die daraus entstehen sind ein Spiegel ihrer Ideologien und Einstellungen. Müssten Technologien, die beinahe alle Menschen betreffen nicht auch demokratische Prinzipien folgen? Wie kann sichergestellt werden, dass Minderheiten in der Technik genauso repräsentiert sind?
Derzeit stehen ökonomische Interessen im Vodergrund, die viel größer sind als die Interessen an Grundlagenforschung. Die Systeme werden schnell entwickelt, der Marktdruck ist groß. Unter Umständen sind die Produktzyklen so kurz, dass die Produkte direkt an den Konsument*innen erprobt werden.
Der Kontrollverlust
Der Kontrollverlust beginnt schon in der kleinsten Einheit, der Undurchsichtigkeit von Microcontrollern und zieht sich weiter bis zu den komplexen, weltweit vernetzten Softwaresystemen. Wenn wir wissen, wie wenig Kontrolle wir haben, sollten wir uns umso mehr die Fragen stellen, mit welchen Intentionen Systeme entwickelt werden. Welche Rolle spielen Ethik oder Empathie in der Entwicklung bei gleichzeitigem Markt- und Konkurrenzdruck? In welchem besten Interesse werden die Produkte entwickelt? Wann und warum halten es die großen Konzerne für ihre Aufgabe, sich mit gesellschaftlichen Folgen der KI auseinanderzusetzen? Welche Verantwortung tragen wir auch mit der Nutzung der Dienste, nicht nur uns selbst, sondern auch anderen gegenüber?
Wir haben es mit Maschinen zu tun, die wir, wenn überhaupt, nur mit unverhältnismäßig hohem Aufwand komplett verstehen können. Wer Technologie sicher benutzen möchte, muss selektiv und bewusst vorgehen. Die Risiken, Abhängigkeiten und Veränderungen werden uns oft erst im nachhinein klar, wenn die Entscheidungen schon längst gefallen sind.